
Do you ever get the feeling that you know a topic is important and that you should know well, but you only understand it superficially? Ever since I got into Rails, I've had that feeling with the Rails router.
Transitioning from ASP.NET, I knew the concept of routing and got comfortable with the router after reading the docs. However, at the back of my mind, I've always had that nagging feeling that I don't REALLY understand the complete picture. I could make the basic routes and resources to get by for the simple CRUD tasks, but whenever I wanted to do something complicated, I found myself fumbling in dark.
Well, after over a year of fumbling and trying to skim the docs and StackOverflow to just learn enough to get by, I decided to dig deeper and REALLY understand how Routing works in Rails.
I've tried to summarize everything I learned in this one giant article. It's over 5,000 words, so don't expect to finish it in one sitting. However, if you can stick through it and read it till the end, I can pretty much guarantee that you'll have a much better understanding of how routing works in Rails. You'll also learn a few nice tips and tricks to clean up and simplify your existing routes right away.
Sounds interesting? Let's get started. Here's what we'll learn:
What You'll Learn:
- What is Routing?
- Routing in Rails
- Digging Deeper: Router Internals
- A Short Detour: the
instance_execMethod - The
matchMethod and its Options - HTTP Method Shorthands
- Understanding the Segment Keys
- The Magic of Named Routes
- Resourceful Routes
- Non-Resourceful Custom Routes
We'll start with the basics, by understanding the purpose of routing in web applications and the role of the Rails router. Then we'll open the hood (i.e. the Rails codebase) and take a peek behind the scenes to understand how Rails implements the routing mechanism.
Then, we'll learn about the match method, which forms the core of most of the routing shorthand methods in Rails, such as get, post, etc. It leads us into covering a few fundamental routing topics such as segment keys and named routes.
Once we've learned the fundamentals, we'll be ready to tackle the practical routing topics, which you'll use day-to-day in your Rails apps. They include the concept of resources and RESTful routes, which drastically reduce the amount of code you write by following convention-over-configuration. We'll wrap up by learning the syntactic sugar provided by router to make it easy to create more expressive routes.
As it goes with all the posts on this blog, I'm writing to clarify my understanding and act as a reference for the future me, but I really hope that you, the reader, find my writing useful in gaining a deeper understanding of the router.
There's a little metaprogramming involved along the way, but don't worry, it's actually very simple to understand. If you need a quick primer on metaprogramming, check out my notes on the Metaprogramming Ruby book.
 Akshay Khot
Akshay Khot
Alright, enough talk. Let's get started. We've got a lot of ground to cover.
What is Routing?
Before answering that, let me ask another question: What happens when someone visits your application? To keep things simple, let's ignore the load balancers, web servers, proxy servers, etc. and just assume the request hits your Rails application server.
What happens when that request reaches your application?
The very first thing that needs to happen is Rails needs to figure out which part of your codebase it should send (or route) that request to, so you can return a meaningful response to the browser. And here lies the answer to the question: What is Routing?
In simple terms,
Routing is the process that determines what code in your application needs to run based on the URL of the incoming request.
Router is one of the first components to run when an HTTP request hits your application. It inspects the incoming URL and directs it to the appropriate Ruby code. Typically, this code will be an action method inside a Rails controller.
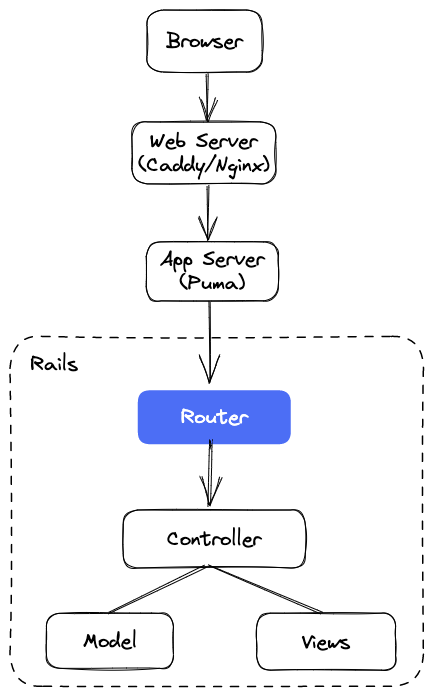
As you can see, the router is the first point of contact for a request inside your Rails application.
After inspecting the URL, the router decides to either:
- forward the request to a controller action
- redirect the request to another URL inside your application, or even to an external website or application
- filter and reject the request based on pre-defined constraints or conditions, e.g. if the user is not logged in, then do not show the
/adminpage.
If the router can't find a route that matches the incoming request, it throws an error.
You can think of the router as a black box with a clear input and an output. Upon receiving the incoming HTTP request URL as an input, the router outputs the controller action where that request must be dispatched.
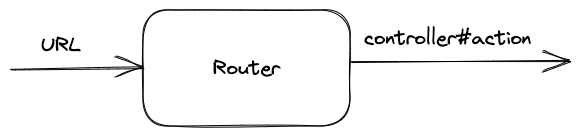
However, the router serves a dual purpose in Rails. In addition to routing the incoming request to a controller action, it can also dynamically generate the URLs for you, so you don't need to hard-code string URLs throughout your app. Not only this approach is more maintainable, it also reads well and makes your codebase more expressive. We'll explore the named routes in a later section of this post.
Now that you know what routing is, let's try to understand how routing works in the Rails framework.