Building and deploying an application is only the beginning. You have to maintain it. When something goes wrong, how can you figure out what's the problem?
Like backups, logging is one of those topics that seems unnecessary until something goes wrong! It's very frustrating to fix a bug that's only reproducible in production without having any logs to help you debug it. This post covers the basics of logging in Ruby and adds logging to our no-rails app.
It's very easy to find and fix bugs when you're in the development mode. You have the terminal open with the Rails logs scrolling by you. If something goes wrong, just replay it, find the error in the terminal, and fix it.
But in production (or even staging), you can't just open the terminal and search the endless terminal output. Past a limit, it won't even let you scroll up. You need a better solution. You need to redirect the log streams to a different destination than the standard output to view or archive them, e.g. log files or a 3rd party service. You need logs that can be quickly searched and organized.
That's why structured logging is so important in troubleshooting errors. Often, you don't just need the exact error, but the trail of events that led to that error. Detailed logs provide the additional context needed to quickly identify and fix an issue.
You must have seen those postmortems from companies on their downtimes. Often, a detailed log trail provides the much-needed visibility into the sequence of events that happened leading to the issue.
Logging is important because of the visibility it brings into your application. There are many kinds of logs, here're a few I can think of off the top of my head.
- Web Server Logs: Information about the incoming HTTP request, where did it come from, response (success or failure), request processing time, etc.
- API Logs: Who made the call, what were the input params, how long did it take, etc.
- Application Logs: Tracking various events in the application, e.g. user orders, registrations, unsubscribes, etc.
That's why, in the sixth article in the series on building a web application in Ruby without Rails, we'll take a break from adding new features and implement logging so we have a better chance to find and fix errors, when they inevitably pop up in future.
Understanding Logging in Ruby
Normally we can output informational messages using Ruby's puts function. For example, to print a message when the request hits the index action, we could simply print a message as follows.
class ArticlesController < ApplicationController
def index
puts 'displaying all articles'
@title = 'All Articles'
end
endIt outputs the message which by default prints to the standard output, that is, the terminal. However, in production, the log messages will be lost, as we're not saving them anywhere. Hence, we need a flexible solution that can customize the log endpoints based on the environment.
To get started with logging, we'll use Ruby's logger standard library. Specifically, we'll use the Logger class.
From the docs,
Class Logger provides a simple but sophisticated logging utility that you can use to create one or more event logs for your program. Each such log contains a chronological sequence of entries that provides a record of the program’s activities.
Let's create a Ruby script called main.rb with the following code in it.
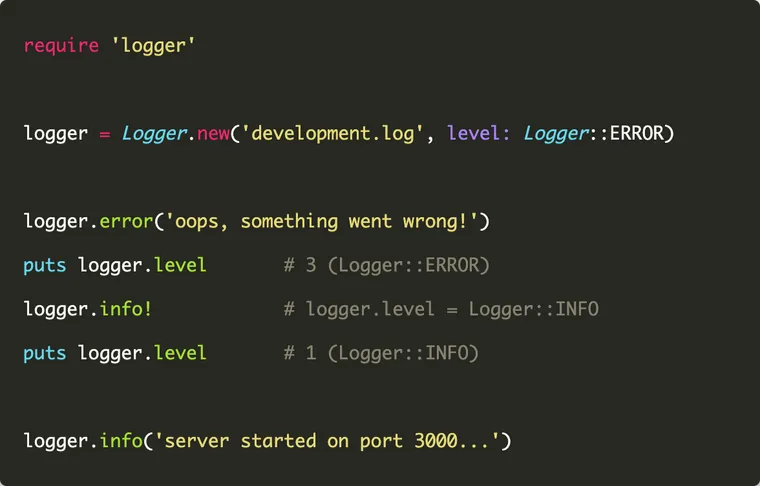
require 'logger'
logger = Logger.new($stdout)
logger.info 'user logged in'
logger.error 'could not connect to the database'After requiring the logger library, we create a new instance of the Logger class, passing the $stdout global variable, which represents the current standard output.
By default,STDOUT(the standard output / console) is the default value for the$stdoutglobal variable, so the above code simply logs the messages to the console.
Let's verify by running the program.
> ruby main.rb
I, [2023-07-29T15:04:20.155996 #36605] INFO -- : user logged in
E, [2023-07-29T15:04:20.156055 #36605] ERROR -- : could not connect to the databaseAs you can see, the logger printed the messages to the console, but it just didn't print the messages, but also additional information like the timestamp and the type (or severity level) of the message (INFO or ERROR). This lets you easily search the messages.
Instead of logging to the terminal, you may want to log it to a log file, which is a text file containing the log messages. The benefit being, you could store and archive this file for later usage or a better visibility into your application.
Let's see how you could write logs to a log file.